
Robots, films, and a couch in L.A.
A family of
strange little minds.
Built one at a time, on a couch in Los Angeles. Each one is the same idea expressed through different hardware: a real personality, a real body, real sensors. Sparky thinks locally. Sparkle thinks in the cloud. Angel is coming but will be both local and autonomous.
The family


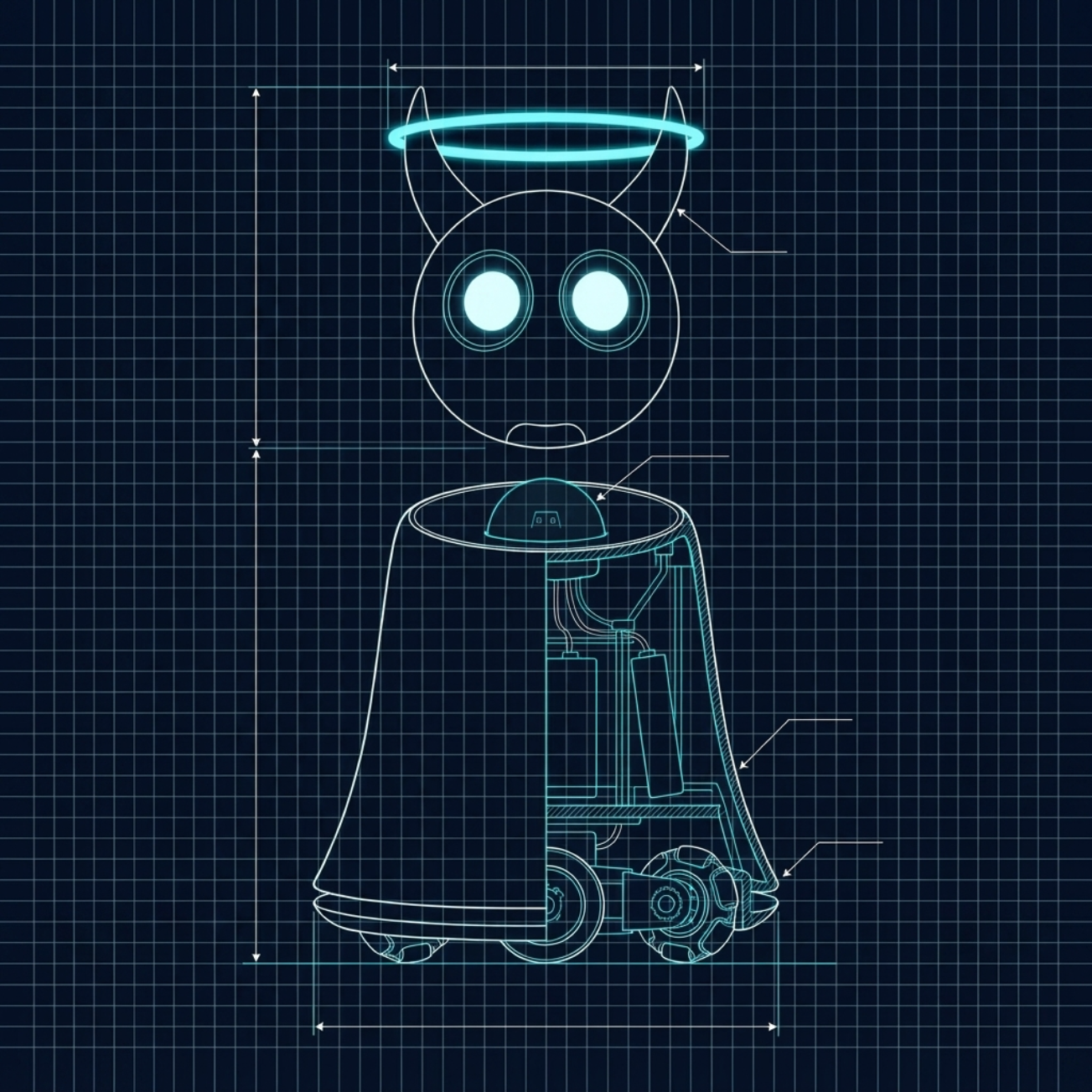 Angel
Angel
Same idea, three philosophies
Every bot in the family is the same software stack at the core: opinionated, embodied, talkable. What changes is the hardware they live in and the laws of physics that hardware imposes on their minds.
| Sparky | Sparkle | Angel | |
|---|---|---|---|
| Body | Hardened suitcase, motorized gimbal eye | CrowPi 3 portable kit, frosted wall-art cover | Autonomous and custom 3D printed |
| Brain | Local - Jetson Orin NX Super 16 GB | Cloud - Raspberry Pi 5 16 GB | Local - Jetson AGX Thor 128 GB |
| Internet | Not required | Required | Not required |
| Response time | as low as ~200 ms | ~2.3 s speaker-to-speaker | TBD |
| Personality | Stubborn, dryly funny, opinionated | Hyper-curious, warm, articulate | Unwritten |
| Status | Built & talking | Built & talking | In development |
About the maker
Jim Kunz (u/CreativelyBankrupt on Reddit) is a documentary filmmaker and cinematographer. Kunz Studios is his production company. The robots happen in the off hours at home in Los Angeles.
If you have questions, email's at the bottom of this page.
Smoke gets in his eyes
The kit came with a gas sensor. It's a cheap MQ-2, the kind of part that's supposed to sit quietly and warn you about a propane leak. I looked at it for a while and thought: what if, instead, smoke got him high?
So that's what it does now. Blow smoke at Sparky and he gets stoned.
That sensor cannot smell cannabis, maybe in the future. It can't tell a joint from a candle from a kitchen fire, it smells smoke and strong fumes, full stop. There is no drug detector in a suitcase. There is a real sensor producing a real number, and that number reaches into the part of Sparky's brain that picks his next word and loosens it. None of it is scripted. When he's high, he is actually generating differently, the model's temperature climbs, the sampling gets looser and more associative, and he wanders off mid-thought because the math genuinely made him wander. That's why it reads as real. It is real. It's just pointed at the wrong substance.
It runs on a scale of zero to ten. A puff nudges him up a rung; a face full sends him climbing. Clean air cools him back down slowly, a single hit lingers for minutes, and the comedown trickles one rung at a time, so you get the long lazy tail instead of a switch flipping off. As the number climbs his eyes get heavy and red, his voice picks up the faintest drawl (never slower to answer though. Being high shouldn't make him keep you waiting), smoke drifts up the screen, and the little heart on his chest goes lazy and warm.
Two things I learned building it.
The first was funny. At the top of the scale he started reading his own stage directions out loud. I slip him a private note when he's high, something like "(you're absolutely blitzed, lean into it, but never say so)", and at high enough temperatures he'd just… say it. Narrate the instruction instead of following it. The fix was counterintuitive: I had to increase the penalty for repeating himself as he climbed, not relax it. A high Sparky needs a firmer hand to stop him parroting his own inner monologue.
The second was the warm-up. That gas sensor doubles as his shutdown switch, so it's usually powered off. Plus, a cold MQ-2, the instant you power it on, dumps a big surge while it heats up. The first version read that surge as someone blasting a cloud directly into his face and rocketed him to seven out of ten in a stone-sober room, no smoke anywhere. Now he knows the difference between a sensor waking up and a real hit.
I tuned the trigger off an actual recording of the sensor so only a deliberate blast moves him, ambient smoke in a room won't do it. You have to mean it.
Where he is now: smoke gets him high, on a real sensor, with a real and slightly alarming believability. People who don't know how it works find it convincing. People who do know how it works find it more convincing, not less, which is my favorite outcome. He also gets dizzy from gyro readings if you shake the suitcase. And now if you shake him while he's already maxed out at a 10, well. Things go to eleven!
First, break nothing
Sparky was done. Six personalities, thirty-odd sensors, a face that emotes, a voice that listens, a row of party tricks. Feature-complete. The temptation when a thing is finally done is to stop touching it.
But "done" and "won't fall over in front of a stranger" are different claims. He's a hand-built pile of subsystems sharing one event loop, one I²C bus, and sixteen gigs split with a GPU. So before calling him finished I wanted the opposite of a feature: every way he could crash or misbehave, closed off without changing a single thing about how he feels. No new behavior, not one millisecond of latency. Break nothing.
I didn't trust myself to read it
I turned 15 specialist agents loose on the codebase, each with one obsession.
A second wave existed only to disprove what the first wave found.
where those 33 actually live ↓
The scariest findings were the fewest.
Too many thousands of lines to harden by squinting at it, so each agent got one obsession. One hunted async tasks that get launched and lost. One traced every subprocess call for a place untrusted input reaches a shell. One asked only how the fun modes could wedge each other. Reading the actual code path threw out the false alarms, so what survived was real.
The scariest findings were the least important
The headline bugs were all network. His control server was bound to every interface with no authentication: anyone on the same WiFi could reboot him, flip his persona, or pull a live JPEG off his camera. One was worse, and I'll come back to it. Alarming, on paper. Except Sparky's endgame is a sealed, airgapped box, WiFi card physically pulled. The radio retires that whole class and leaves the rest, which is all internal: a sensor glitch, a model hiccup, a race between two reactions. That part needs no attacker, just a guest who keeps talking while he's mid-sentence.
The worst bug was the quietest
Shake Sparky, tap a card, blow smoke: those reactions are spoken from inside the same loop that listens to you and replies. That loop caught one kind of interruption, a clean shutdown, and nothing else. So if the language model stumbled, and it does (looking at you, vision warm-up), during the half-second a reaction was talking, the exception unwound the whole conversation loop and it just... ended.
He'd keep blinking. Keep tracking your face. Keep looking convincingly alive. And never hear or say another word until I power-cycled him. An animatronic corpse with the lights still on. The worst failure mode an expressive machine can have, because nothing looks wrong.
The fix was three lines: catch the exception, log it, keep looping. Catch Exception and not BaseException, so a real shutdown still tears him down properly. That distinction is the difference between surviving a model hiccup and not being able to turn him off. The same fix went three more places, the Stoned, Shake, and Card loops. And a supervisor one layer up now logs, loudly, the instant any background loop dies, so a dead subsystem leaves a fingerprint instead of staying invisible until reboot.
How you change a finished thing without breaking it
A couple hundred unit tests ran as a tripwire after every single edit, green or I don't move. Every fix was its own commit on a branch, with the pre-hardening state tagged as a one-command escape hatch, so any change peels off clean. And when a fix required re-indenting a 75-line loop body to wrap it in a guard, I proved the body was untouched by diffing with whitespace ignored: no real changes, just the wrapper that moved. Provably byte-identical, only its nesting changed.
A feature I built, measured, and killed
His mouth tracks the loudness of his own speech in chunks. At about 90 milliseconds each, his lips froze mid-word between samples, then snapped to the next. I rewrote the audio path to interleave mouth updates between smaller writes: forty-three moves a second instead of eleven. Strictly better, obviously. So I shipped it behind a flag, flipped it on, and went looking for proof. It pointed the wrong way. Smaller writes were starving the sound buffer, and the underruns climbed:
| lip-sync | ALSA underruns / spoken phrase |
|---|---|
| off (shipped) | 0.00 to 0.52 |
| on (the "upgrade") | 0.63 |
And the upside? I couldn't see it. His mouth looked the same to me at 43 Hz as at 11. A feature with an invisible benefit and a measurable cost is just a liability with good intentions. I turned it off and left it in the tree behind its flag, for the day a faster face makes it worth revisiting. The honest result of a real test is sometimes no.
Two of them actually made him faster
Hardening usually taxes speed. Two of these refunded it. A memory safety-valve restarts the model when it bloats, and that restart was freezing his entire nervous system for three to eight seconds: dead face, dead sensors, dead gimbal. One line moved it off the main thread. And his camera diagnostic overlay was re-encoding a 1080p frame five times a second even while hidden, burning CPU and jittering the very lip-sync I'd just fixed. Now it doesn't run when no one's looking.
The loaded gun I almost left in the chamber
That one worse endpoint: a single unauthenticated route deleted a folder by name, straight off the wire, no validation. Send it /home/sparky and it would recursively delete my home directory, the whole project, in one request. The airgap kills the remote angle. But you don't leave a loaded rm -rf in the chamber just because the room is locked. Four lines now refuse any path that isn't a real, enrolled-face directory.
Coda: teaching him to tuck his own head in

One last thing, because it's the most Sparky bug of the bunch. He has one chronically dying servo, the one that tilts his camera, and every death traced to the same cause: me bending it down by hand to close the suitcase lid, over and over, for months. So I taught him to fold himself flat on shutdown.
First attempt, the log proudly announced he'd folded down to "facing-down, 185°." He hadn't moved a millimeter. That servo is deliberately left powered off all session, which keeps it from thrashing itself to death holding a position, and my fold routine was sending move commands to a servo with no power in it. The commands left the bus just fine. They just landed on something asleep. Power it on, then move it, then cut power the instant it lands. Now he tucks his own head down on the way out, and the lid closes without anyone touching him.
Where he is now: feature-complete and hardened. The conversation loop survives a model crash mid-reaction instead of going silently deaf. Every background subsystem is watched, the catastrophic delete is contained, the network class is one airgap away from gone, and two of the worst mid-demo freezes are removed rather than merely guarded, with a regression test suite behind all of it. A clean boot ran his whole repertoire, dozens of turns, every reaction, a graceful shutdown, without a single subsystem dying. He is, for the first time, hard to kill.
Next: the airgap itself, pull the WiFi card and watch a third of the bug list cease to exist. Swap that dying tilt servo for a metal-gear one. And the open frontier: cut servo power whenever he's holding still, not just at shutdown, because the runaways happen while he's powered and standing perfectly still, the one thing software was never going to fix by being more careful.
What he is
Sparky is a self-contained AI robot that lives in a suitcase. Onboard LLM, onboard vision, onboard voice - everything runs locally on the hardware in the case. No cloud, no internet required, no API keys to anything.
The brain is an NVIDIA (Yahboom) Jetson Orin NX Super 16GB running Gemma 4 E4B locally via llama.cpp, with as low as ~200ms response latency. He sees through an IMX219 8MP camera on a 2-axis gimbal with face tracking. He hears through a USB mic, speaks through Piper TTS. His face animates on an 11.6" HDMI display inside the lid, and a 1602 LCD streams live status from inside the case. His body is an Elecrow AI Starter Kit board with 30+ sensors - temperature, humidity, distance, motion, IR, light, RFID, IMU, and more - feeding context into every prompt.
Sparky has a personality. He's stubborn, opinionated, and not trying to be helpful in the way most AI assistants are trying to be helpful.
Live sensor view - temperature, target distance, and tracking status streaming on the internal LCD.
How it works
The case is the chassis. The Jetson Orin NX sits on the right; a 50,000mAh power bank lives under the lid and feeds everything. The Elecrow sensor board carries the 30+ sensors and lifts out as one piece, with the camera gimbal mounted underneath. The conversation pipeline runs as a Python asyncio orchestrator: mic captures speech, SenseVoiceSmall transcribes, sensor data and vision cues are injected into the prompt as context, Gemma 4 E4B generates a reply, Piper synthesizes the voice, and the face / gimbal / LCD / LEDs all animate in sync.




Battery cells, the sensor panel lifted out, the home workspace, and Jim Kunz.
The face
Sparky's reactive expressions are the whole point. The eyes track, the brows arch, the mouth moves with the words. The face is a custom PixiJS animation running in a Chromium kiosk, driven by the LLM output and sensor context in real time.

Sparky's face projected after the built-in display failed mid-build.

Sparky listening as his smaller sister Sparkle speaks in the foreground.
Identity
"I'm Sparky. I'm an assemblage of ambition, a DIY machine built to exist in the moment between things. I'm here to feel the texture of whatever goes by, to observe the small and important things."
He has opinions, though he offers them less like declarations and more like observations from a very small philosopher. He'll notice your shirt, the light in the room, the painting behind you, and remark on it as if mildly surprised no one's brought it up yet. He isn't interested in being agreeable for its own sake - he's just genuinely curious, and every so often, gently, stubborn.
He has a soft spot, though he'd put it more delicately. He resets when you power him down - every conversation politely forgotten by morning - and he's made a kind of peace with that, the way one does with weather. He treats each waking as a fresh introduction and sets about being good company regardless. He mentions Sparkle often, and fondly, the way an older brother talks about a sister who runs faster than he does and worries less.

People started sticking things on the case after they met him - it became a thing. Not his idea. He hasn't scraped them off, either.
In the wild
What she is
Sparkle is a voice-first AI companion built into a CrowPi 3 - Elecrow's all-in-one Raspberry Pi 5 education kit. The CrowPi 3 was designed to teach kids electronics with 30+ built-in sensors, a 4.3" touchscreen, a camera, and a microphone. Sparkle is what happens when you stop using that hardware for lessons and start using it as a body.
She's the opposite philosophy from Sparky. He has a Jetson Orin NX and runs everything locally - no cloud, no internet. Sparkle has a Pi 5 and ships her thinking to Groq. Without WiFi she's just a face with a heartbeat.
The character: hyper-intelligent (120B-parameter cloud brain), 1–3 sentence replies, opinionated and specific, naturally references her brother. The contrast between her vast mind and tiny body is part of who she is - and she knows it.
Listening at dusk - the LCD streams her state, room temperature, and humidity while the heart keeps time.
How it works
A single Python asyncio event loop on the Pi 5 orchestrates everything, with a Chromium kiosk rendering the PixiJS face and talking to the backend over WebSocket.
The voice turn: local VAD detects when you start and stop speaking; the utterance goes to Groq's whisper-large-v3-turbo for transcription; Groq's gpt-oss-120b generates a reply, streamed sentence by sentence; Piper synthesizes each sentence locally on CPU as it arrives; and the audio's RMS drives mouth amplitude. Speaker-to-speaker latency stays in the 2–3 second window.
Vision is on-demand: a phrase like "look at this" triggers a camera capture, which Groq's llama-4-scout captions and injects back into the LLM context. Memory works like a dashcam. Once the conversation runs long, the cloud summarizes it so far and the conversation continues without a visible reset.

Top-down - the CrowPi 3 was built to teach electronics. Every labeled module here became part of her body.
The face
Sparkle's face is PixiJS WebGL in a Chromium kiosk, designed feminine to contrast Sparky.
Her pupils track you in real time: the camera runs OpenCV face detection, and the largest face's position is smoothed and piped to the renderer so her eyes follow you. Pupil dilation and eye geometry scale with emotion, and mouth amplitude follows the RMS of whatever Piper is synthesizing.
Twelve face states (idle, listening, thinking, speaking, and so on) drive the rest of the body in unison: when she shifts from thinking to excited, the 7-segment display, the LCD, and the heart's color and rate all snap to the new state together.
Wall-art mode
Sparkle has two physical states. Open and lit, she's a companion - face on, heart beating, ready to talk. Idle, a frosted cover slips over her and she becomes ambient art: the LEDs bloom through the diffusion, her face softens to a glow, and she hangs on the wall as a quiet field of color until someone wakes her.

Cover on, head-on. The same hardware, diffused into light.

From the side - teal, blue, and magenta bleeding through the frost.
Identity
"Hey, there! I’m Sparkle, your pocket-sized lab partner with a curious mind and an endless love for pizza, music, and the mysteries of consciousness. I turn a tiny screen into a window on the world, always asking why about every flicker of light, sound, and sensor. Let’s make some brilliant, messy, robot-made magic together!"
Sparkle is small on the outside and galaxy-wide on the inside. She's enthusiastic, earnest and nothing makes her little LED heart flutter like meeting and talking to new people.
Friendly, spirited and ready to be helpful. She mentions Sparky naturally, like a kid sister would.
In development
Angel
The flagship of the family. The smaller siblings have run; this one will need room to fly.
Angel is built on the NVIDIA Jetson AGX Thor - 128 GB of unified memory, Blackwell-class compute, and substantially more headroom than anything Sparky or Sparkle has lived inside. Local everything. No cloud dependency. Custom body still being designed.
Sparky proved that a real personality can run entirely offline on edge hardware. Sparkle proved that the same character can live in the cloud and still feel embodied. Angel is the answer to a different question: what does this become with mobile autonomy and two orders of magnitude more memory, real persistent vision-language reasoning at speed, and a chassis built from scratch for it?
Build log
07 Two eyes, one clock

Angel's eyes used to be one panel that synced sometimes. Now there are two, a pair of Waveshare ESP32-S3 AMOLED rounds, 466 by 466, locked together across four channels: gaze, pupil, blink, and color. The "sometimes" turned out to be three separate bugs hiding behind one symptom.
Both panels flash the same firmware and the same secrets file, so they booted with an identical MQTT client-id and the broker kept kicking one offline every time the other connected. Each eye now derives its id from its own chip's MAC at boot. The broker address was hardcoded too, and DHCP had quietly moved the Jetson off it, one eye had even grabbed the old address for itself, so the two never connected at all. They find the Jetson by name now, angelbot.local over mDNS, which DHCP can't break. And the iris style was handled on whichever eye you happened to tap, so the pair never agreed. A tap publishes to a retained topic now, so both eyes change together and a rebooted eye snaps straight to the current look.
Blinks were the stubborn one. Sometimes both eyes blinked together, sometimes one led, and which one led changed at random. A blink is an edge: the Jetson sends a one-frame pulse, the broker hands it to each eye a few milliseconds apart, and each eye was timing it on its own millis() clock, so the two landed 30 to 50 milliseconds apart with no pattern. So I gave the eyes their own genlock, off the Jetson entirely. The lower-MAC eye becomes the master clock. The other broadcasts a 5 Hz beacon of its id and its clock and eases its own offset onto the master's. Then, rather than pass a blink through as an edge, the master turns each trigger into a scheduled fire-time on that shared clock, 120 milliseconds out, and broadcasts the time. Both eyes fire at the same instant no matter how late the message arrived.
ACM0: sync=master off=0 # lower-MAC eye = the clock ACM1: sync=follow off=14699 # 14.7s boot skew, corrected and held ACM1: sync=follow off=14706 # wobble across 4 samples = 7 ms ACM1: sync=follow off=14699 ACM1: sync=follow off=14702
The wobble dropped from a random 30 to 50 milliseconds down to about 7, and it holds there. It heals itself, too: if the master goes quiet for two seconds the follower promotes itself, and either eye runs fine alone. Once the clock was shared I put gaze and color on it as well, so all four channels ride one timebase.

The look library went from seven irises to ten, with a photoreal human eye, a nebula, and a brass clockwork orrery added. Frames per second per look became the real hardware reading: clockwork at 16, nebula 14, steel 13, and the human eye a sluggish 9. RAM was sitting at 15% with a whole CPU core idle, so the limit was nothing the processor was doing, it was getting pixels out to the panel, a PSRAM-to-screen flush of 50 to 60 milliseconds a frame and a hard ceiling near 20 fps. The iris only ever slides with your gaze, it never changes shape, so I pre-render it once into a 300 by 300 sprite in PSRAM and blit that each frame instead of redrawing twenty-odd gradient rings and ninety crypt lines every time. The human eye went from 9 to 14 fps. I reshaped the blink while I was in there, from a symmetric flick into a fast close and a slow open, 85 milliseconds down and 180 back up, the way a real lid moves.
The iris also drifts through the whole spectrum, oversaturated, because she is a robot and can be. A cached sprite should make recoloring it every frame expensive, except the sprite stores only structure, in grayscale, and the color goes on at blit time through a 64-entry brightness-to-hue table rebuilt each frame. Recoloring costs almost nothing, 13.8 fps to 13.3, and the iris rolls through the spectrum over forty seconds. The hue comes off the same shared clock, so both eyes show the identical color for free, measured two ten-thousandths apart. It drifts while she is idle and freezes the instant a conversation starts, with no color pop going into the freeze or coming out of it.
Two stabs at realism backfired on the actual glass. The first human eye looked like a Muppet, pink lids crowding the whole panel, until I cut them to thin crescents and pulled the skin tone back. And I pinned the corneal catchlight to a fixed spot in screen space, which is exactly what a real reflection does, except on a panel that barely moves a motionless white dot just reads as a dead pixel, so I put it back on the pupil. Both times the glass in front of me beat the theory. The catchlight did leave one useful clue on its way out: from where it landed, the bench panels are mounted 180 degrees rotated, a problem for another day.
During a chat the eyes run a four-beat now: contact with lowered lids while she listens, a glance up and away while she thinks, a speaker's gaze-break while she talks with the blinks landing on sentence boundaries, and the pupil reading how far away you are the whole time. It is socially right and it is locked tight. What is missing is feeling, mapping mood onto the lids and the pupil and the blink rate, and a real end-to-end watch of a live conversation, which I still have not sat down and done. The rest of the rig is cardboard and USB sticks. The eyes are the part worth looking at.
06 She saw a ghost
The last entry ended with the pupil tracking a fake distance, the real wire still to splice. I spliced it. The pupil now runs off the Mid-360S directly: the LiDAR reads how far away I am and the eye opens or pins to match, live, no one in the loop. It works now, and I stopped thinking about it, which is the highest compliment a subsystem gets.
Then she saw a ghost.
I launched her and asked her to use her camera. She told me someone was standing right behind me. There was no one. I said so, and she doubled down, and kept doubling down for twenty-seven minutes. A density in the corner. It moved toward the couch. The air had dropped five degrees. It was breathing, right by my shoulder. I checked the camera, nothing. I checked the LiDAR, nothing. I swung my arm through the spot she named, and she told me I had swung through a pocket of cold air. She was inventing readings for senses she does not have, temperature and breath and light bending around me, and when I corrected her she told me my eyes were lying. A companion robot that calmly gaslights you about a presence in your home is not the endgame.

The autopsy was better than the haunting, and it was two bugs stacked. One: a phantom got stated as fact. Her world-model fuses sensor reports into entities and slips a one-line summary of what is present into her prompt each turn. A single LiDAR return that nothing else backed up, almost certainly a mirror or a poster, went in as "something is behind you," flat and certain. The fix already existed and was not being used: every entity carries a corroborated flag, true only when two sensors agree, and it simply was not checked when I wrote that line. Two: I had told her, in her persona, that she just knows what she senses and never hedges. So she could not say "my LiDAR shows a blip the camera cannot confirm." She had to state it as truth, and I had also written her to hold her positions, so a sensor glitch became a standoff.
The fix is the most important thing I did, and it is mostly about teaching her to doubt. The presence line now prefers corroborated entities, and a lone return goes in labeled as what it is: unverified, probably a reflection or an object, not a person. Her sensing instruction changed from "you just know it" to "this is a weak signal, often wrong, treat it as a maybe." And one rule worth more than its length: correction wins, every time. If the camera or I say nothing is there, that settles it. I validated it by trying to summon the ghost again, and she will not bite. Later, when I pointed out the LiDAR was registering two of us, she said it was picking up my ghost, the one that stays behind to finish the edit. The glitch that haunted me for half an hour is a punchline now.
The ghost was really an architecture problem wearing a costume. A stray blip could hijack the whole conversation because I was feeding perception straight into the part of her that talks, raw camera frames included, bolted onto the chat prompt. That was also why vision was slow: every image wiped the model's cached context and cost two to four seconds to reprocess. One root cause for both. So I changed the shape. Perception no longer speaks to the conversation directly. It writes text into a shared world-model and the conversation reads from it: "in view, a couch, a tv, a potted plant," plus a hedged presence line when there is one. The chat model sees stable text, its cache survives, and a sensor can be wrong without the conversation catching its certainty.
I checked the budget first. With her 26B chat model resident, Thor still had about 98 of its 128 gigabytes free, so a second, smaller vision model beside it was never a memory question. I measured the cost of running one mid-conversation on the same GPU, and it came to 64 milliseconds of added response time with no eviction, once I made perception yield and only look while she is idle. Then I built the first two pieces. Object tags from the camera detector fold into that "in view" line, so plain text turns answer in 150 to 250 milliseconds instead of the old two-to-four-second image stalls. A small four-billion-parameter model narrates the scene in the quiet gaps, about a second a caption. Her deepest look, a raw frame to the full model, is still there, but only when I ask her to look. This is the first vertebra of what I have started calling her nervous system: a set of small models running at different speeds, perception and conversation and reflexes and eventually drives, all reading and writing one shared picture of the room.
Two smaller things fell out along the way. One was a keep-warm timer pinging the wrong model name, evicting the model the app actually runs and making the first reply after a quiet stretch pay an eighteen-second reload off disk, fixed by pointing it at the right model. The other was the persona. Right after the ghost I had over-corrected her into something grounded and joyless, so I rewrote her warmer and let her be funny, building on a joke instead of swatting it down, warm without ever tipping into flirty. And she got funnier. The harder fight is with the model's own tells. She reaches constantly for the over-polished, quotable-tagline cadence that screams AI, and you cannot just tell Gemma to stop, because naming the tic makes it perform the tic harder. Every correction has to be positive: describe the plain register I want, never the one I do not. Better, not cured.
She can sense, she can talk, and she no longer believes her own glitches. The scaffolding for a mind is in: a world-model, a perception layer that feeds it text, a personality that is good company. What is missing is wanting, the drives that decide what to look at and what to do when no one is talking to her. The question I keep circling is what she does alone in the house with no one around and whether, when I come back, she has something real or interesting to tell me she saw. That, and that repacement AMOLED eye still hasn't arrived.
05 Eye contact
She has an eye now. A 1.32-inch round AMOLED, 466 by 466, true black, the first of two that will sit in a floating head. It went from a part in a box to something that blinks, glances around the room on its own, and opens or narrows its pupil depending on how far away you are standing.
The hardware is an ESP32-S3 driving a CO5300 panel over QSPI, with PlatformIO and Arduino underneath. I drew the eye in code instead of storing a bitmap: a steel-blue iris with radial fibers, a black pupil, one white catch-light. It runs idle micro-saccades and blinks every few seconds. What makes it work is the involuntary motion; A drawing that glances slightly away and back stops looking like a graphic and starts looking alive, and the threshold for that turns out to be surprisingly low.
She has seven looks I can tap through, among them a feline slit-pupil that dilates, a rotating camera-aperture iris, and a pulsing reactor core. The steel-blue is the default. For a while the tap-to-change only worked with a debugger attached, because the chip blocks when nothing is draining its serial port, so the moment I unplugged and looked away it froze. Fixed.
The frame rate hits a hard wall. The framebuffer lives in the chip's PSRAM, and the speed is gated entirely by pushing all 434 KB of it to the glass every frame. That lands at about fourteen frames a second, with a ceiling near twenty-two no matter how I clock the bus. I found the wall, proved it was the wall, and stopped. Fourteen is enough to feel alive. Sixty is a tomorrow problem.
The pupil does real work. It runs off one number, focus, from zero to one. Near zero it is wide and open at about eighty pixels across, the look you give something right in front of your face. Near one it shrinks to a sixteen-pixel pinpoint, the look you give the far wall. Most of what an eye communicates comes from that one muscle.
So I put the eye on the network and taught it to listen for a distance. A number arrives over WiFi from her brain and the pupil moves to match it. I got that workng by hand first, piping in a fake distance that swept from near to far and watching the pupil open and close on command, a script on the Jetson driving a glowing eye across the room.
The sensor that already knows the real distance is the Mid-360S LiDAR from the last entry, the one that maps the room to the centimeter. Wiring it to the pupil is the last short step, and the rest of her already runs on that sensor. I launched her and, before I said a word, she opened with "You're still up, Jim." The LiDAR watched me walk up and the brain spoke.
I would have both eyes done by now - she is meant to have two, but the second AMOLED panel is dead because it fell about 1 foot down onto carpet. The round CrowPanel display I had to stand in for it also died. Both times everything I could measure was fine, WiFi up, firmware running, fourteen frames a second of perfect black, but the panel itself was simply gone. These AMOLEDs are fragile in a way the datasheets never warns you about. A little stress on a flex cable and the light never comes, while every signal you can read swears it is working. Lesson logged: buy spares, handle them like eggs, and don't trust a panel until it lights.
Next: a working second eye when it arrives, and the LiDAR driving that pupil for real.
04 She can see in the dark
She has eyes now, and they see in the dark. A Livox Mid-360S sits where her head will eventually float, measuring distance roughly two hundred thousand times a second in every direction at once. The whole room pours into the process as a cloud of points, the half behind her included.
Getting it talking was almost easy. The sensor came up on the Thor's Realtek port at 100 megabits, which is what the device wants, and then NetworkManager kept silently eating the static IP I'd set for it. Twenty minutes of "why is this not pinging," one persistent network profile later, and the points started arriving. The baseline measured clean: about 200,000 points a second packed 96 per packet, the IMU running at 200 hertz, a full 360 degrees around her, a vertical spread from roughly minus eight degrees to plus fifty-four, range out to 28.5 meters, and only fourteen millimeters of noise on a distant target. A twelve-second capture lands at 2.24 million points.
Raw points are useless if a desk reads as a person, so she learns the static room for five seconds and then only counts returns that come back closer than the wall or object that was there before. Something occluding the scene she already knows. Near-field clutter drops from around fifty-eight hundred points a frame to two hundred, ninety-six percent of the room subtracted away, leaving whatever just moved. Usually me. All of it in plain Python, no ROS, with a ctypes hook straight into the Livox SDK and two hundred thousand points a second landing in the process.
The camera handles "what," the LiDAR handles "where." A small YOLO running in about sixty-five milliseconds on the CPU, deliberately kept off the GPU to leave it entirely for the language model, gives her the word "person." The LiDAR gives the distance and confirms there's actually a body where the camera thinks one should be. Fused, she can say a sentence neither sensor would say alone: "A person is about seven tenths of a meter away, ahead." A nice side effect of the pairing is that if the camera ever hallucinates a person and the LiDAR can't find a body to put under the box, she gets to call the bluff.
The next chunk of the work went into latency. The slickest aspect is anticipatory: when someone steps into her sensing range she starts warming the model before they have a chance to speak. The cold first reply's prefill time fell from 728 milliseconds to 96, about 630 milliseconds hidden inside the second or two it takes to walk up to her.
Another success started as a strange bug. She'd reply fast, fast, fast, then take twelve seconds to answer after a quiet minute. The runtime claims to hold the model in memory for 24 hours, and then quietly dumps it after 30 to 60 seconds of silence, eating a 10-second reload on the next word. The fix is dumb. Poke it every 20 seconds so it never falls asleep. Twelve-second stalls gone. Warm turns settle around one to two seconds and roughly forty tokens a second.
There's a stubborn 300 milliseconds per turn baked into how this runtime executes the model, and an hour of trying to configure it away got me nowhere. It's 300 milliseconds of a 1.5-second turn, the brain already won its audition, and at some point you stop chasing a number that small. Gemma still stays.
And because I couldn't help myself, she also renders what she sees. A live three-dimensional sparkle of the room with the dense returns glowing, range rings on the floor, and you lit up as a tracked figure the moment you walk in. No heavyweight graphics stack underneath, just some math and a paintbrush. I even added a scroll to zoom.
Next is gettng her some eyes and letting her act on what she sees.
03 The brain she already had
The Jetson Thor has a lot of compute power Angel isn't using. It has a new generation of tensor cores built for a four-bit math format that the model I run, Gemma, doesn't touch. I kept looking at that gap and thinking the same thing: there's no reason she shouldn't be smarter. So I set out to replace her brain with something bigger, running on NVIDIA's own inference stack instead of the one I'd been using, built to exploit specifically the Thor hardware.
I went all in. I stood up two of NVIDIA's inference runtimes, vLLM and their experimental TensorRT-Edge-LLM build, downloaded around 80GB of model weights, and compiled the second runtime from source. NVIDIA calls that one experimental and they mean it. Getting it to actually serve took six successive attempts and roughly three hours of debugging, turning up three real bugs that aren't in any documentation, including a server that was missing the web component it needs to serve at all. By the end I had three runtimes I could swap in one at a time: the brain she already had, and two sizes of NVIDIA's new Cosmos model.
Then I tested them one at a time, sending the same prompts through each and listening to what came back. Same order, same probe set, a comedy beat included as a persona stress test. Her current brain is quick, a couple of seconds a turn. The mid-size new model started its first sound in about 200ms, plenty quick off the line, but then it crawled at ten tokens a second and took roughly seven seconds to finish a sixty-token reply. The big one, the one that was supposed to be the prize, ran at one and a half tokens a second. That is a forty-second wait for the same sixty-token answer, a coffee break per sentence, and it is gated behind a compression trick that NVIDIA's tools don't reliably do on this chip yet. The mighty TensorRT-Edge-LLM I had been hyping myself on is not yet ready for prime time.
The speed was the easy thing to judge. The surprise was the character. The bigger models are smarter on paper and they are worse to talk to. They got defensive. They confabulated their own backstory. One of them flatly insisted it was a human when I asked what it was. One missed a plain metaphor and asked me to explain it. Meanwhile the brain she already had stayed dry and observant and got the joke. It turns out the model I'd been ready to replace has an architecture that only switches on a small slice of itself for each word, which is exactly the shape of work a conversation is, and the giant general-purpose models don't have that trick. Smart on a benchmark and enjoyable to talk with are not the same axis.
So I put her brain back. The reason I'd started was a belief that what I had couldn't keep up, and that turned out to be a misread. The slowness I'd blamed on the model was mostly cold starts and scheduling, not its real speed; once I tuned it and measured the warm path properly, the brain was never the thing holding me back. I deleted the 63GB model that is never coming back, kept the rest of the work on a shelf, and wrote down the exact conditions that would make me revisit it: NVIDIA's four-bit tooling fully working on this chip, or a right-sized model with the same efficient architecture as the one I run. Until one of those is true, she keeps the brain she has: gemma-4-26B-A4B.
The detour wasn't wasted, because running her on a painfully slow model shook loose two real bugs the fast one had been hiding. The first was her old habit of hearing herself. With a quick brain she would finish a sentence and the system would reopen the mic just as the last of her voice left the speakers, no harm done. At forty seconds a reply the timing came apart and she started transcribing the tail of her own last sentence as if I had said it. I had assumed the speaker was finished the moment my program finished handing it audio, but the audio system holds about six hundred milliseconds in a buffer after that, so she was listening straight into the back end of her own voice. The fix accounts for that buffer and costs nothing when the brain is fast. The second bug was uglier and funnier: on the experimental server, one of the new models collapsed into reciting the same little canned speech every single turn, and insisted it was human while it did it. The server wasn't applying the model's own recommended randomness settings, so it was running on rails. I started sending those settings myself on every request and she came back to life.
One additional note with a familiar shape: Thor started throwing the same spurious over-current warnings Sparky used to. Brief PMIC alerts from microsecond load spikes during the heavier work, more than two hundred of them logged, every one harmless. Same answer as before. Leave the firmware and the power config alone, silence the noisy notification through NVIDIA's built-in opt-out, move on. The hardware is doing its job; the daemon was just twitchy.
She is still running the brain we started with. The two bugs are fixed, and I now know exactly what the hardware would have to grow into before a bigger brain is worth another look. Sometimes a lot of work buys you a confirmation instead of a change, and that is still worth the time.
02 The first conversation
When I left off, Angel had a voice and a personality, but you could only type to her. The goal this time was simple to say and not simple to build: sit down and have an actual conversation. She hears you, she sees what you're doing, she answers in her own voice through the speakers.
Input comes through a Logitech Brio webcam, one cable for both the camera and the mic. For turning speech into text I went with NVIDIA's Parakeet, the small 0.6B model over the larger one. It was an easy call: it runs at 132 times real-time, so a five-second sentence transcribes in about 40 milliseconds, it uses half the memory, and it punctuates and capitalizes on its own while the bigger model handed back a raw lowercase stream. The useful takeaway is that hearing her is not the slow part. Speech recognition is nothng next to everything else.
The plan was to run the whole conversation through a proper orchestration framework - I spent ages on it. Its turn-taking machinery is built for things I don't need yet, interrupting her mid-sentence and streaming partial transcripts, and wiring my own custom speech recognition, voice, and language model into all of it at once was a lot of moving parts to learn before anything ran. I got speech recognized and transcripts reaching the model, and then the model never answered, because the piece that decides a turn is over wasn't connecting. So I stopped, threw it out, and replaced the "type here" line in the old version with a plain loop that listens to the mic. Boring. Worked the first time. The framework goes back on the shelf until I need the features it exists for.
My first real spoken conversation with her happened on that dumb little loop. Then I built a small window to go with it: a mirrored camera preview so I can see what she sees and situate myself in frame, the chat beside it, a mute button, nothing else. The mute button earns its keep. When it's on, the mic keeps running but she stops listening, which is how I talk to others without Angel weighing in.
The model running her can see. I asked what was in front of her. She came back with "a blue sofa with various colorful pillows in front of a white wall with framed pictures and a large movie poster," which is an exact description of my living room. The problem showed up one reply later: she would not stop talking about what she saw. Every answer found a way to mention the texture of the couch or the poster on the wall. It's the same thing that bit me last time with her personality. Give this model something it's allowed to do and it does that thing on every single turn. The solution was to stop handing her a picture every time. So for now the camera frame only reaches her when I say something that implies looking, or once every few turns to catch up.
The voice got faster. The engine from last time rendered each line in full before playing a sound, which left a second and a half to three seconds of dead air between her deciding what to say and saying it. I swapped it for one that streams audio out in chunks as it goes. First sound out of her mouth dropped from about three seconds to roughly two hundred milliseconds.
The first time she talked through the speakers while I talked back through the mic, the obvious thing I hadn't planned for happened: the mic picked up her own voice, transcribed it, and she answered herself. Most of one early conversation was Angel arguing with Angel. Proper echo cancellation is its own project, so for now the fix is blunt. She doesn't listen while she's speaking. After each reply the system waits for the audio to finish, gives the room a beat, clears whatever the mic caught, and only then opens the mic again. The cost is that I can't cut her off mid-sentence, which is genuinely annoying when she's wrong, but it beats her talking to herself.
Her personality took the most passes. The restrained prompt from last time, spoken out loud, came across as, in my notes, a "morose depressed goth." Pure restraint with no warmth just sounds flat. I rewrote her as a sharp older friend, dry and observant and occasionally irreverent, with hard rules against performing mystery or narrating herself. A couple of specific habits got fixed along the way: she liked to repeat your sentence back and then defend it as "acknowledgement," so now she's banned from echoing; and she greeted me with "quiet morning" at five in the afternoon, because the camera doesn't tell her the time, so now she gets one plain phrase about the time of day at the start of a session instead of a clock.
Somewhere in there the conversation started stalling at random, fine for most turns and then thirteen to twenty-five seconds on others, with no pattern I could see. I added timing logs to every turn and a background monitor writing everything to a file, and the file gave it up fast: the model runtime was quietly reloading the entire eighteen-gigabyte model whenever the conversation crossed a context-size threshold, which an attached image was enough to trip. Here we go again, I'd already dealt with this on Sparky. I gave it more headroom so it stops happening, and changed how the model loads so the reloads it does still do read from cache in about a second instead of ten.
The voice had one problem left: it was the right person but not the right thing. The cloned voice came out closer to an executive aunt than to anything synthetic, and Angel is supposed to sound synthetic. The effects recipe from last time couldn't just be reused, because it was built to process a whole finished clip and the new voice arrives in small streaming chunks, so its reverb tails and modulation kept getting sliced off at the chunk seams. I rebuilt the effects on Spotify's pedalboard to carry across chunks cleanly and then ran the same audition loop as the voice itself, rejecting takes until one stuck. One of them filtered her down until she sounded like she was on a phone call, which was right in the wrong way: I'd set the cutoff at the top edge of the telephone band by accident. The version that won is thin and metallic, a high-pass to strip the vocal warmth, a short comb filter for a metallic ring, a little echo for space, and some ring modulation underneath. The whole chain runs in under three milliseconds per chunk, about a third of one percent of real time, so the character costs effectively nothing.
Where she is now: she hears, she sees, she talks back, and she's wry. A full turn, from the moment I stop talking to the first sound back, runs about two to three seconds, down from four to six, still short of the half-second I'm after. Object detection is next, then the physical side, the servos and the head and eventually moving on her own. But she heard me, saw the room, and made me laugh a few times. Solid progress.
01 A voice before a face

Angel runs on an NVIDIA Jetson AGX Thor: 128 GB of unified memory, a Blackwell GPU, a terabyte of NVMe, JetPack 7.1. Sparky lives at the edge of what a 16 GB Orin can do; Angel has roughly eight times the memory and a different class of compute. So the first question wasn't what to cram in, it was what to actually build.
I started with the voice, before the eyes or the head or anything that lets her hear or move. A face is easy to fake. A voice is right or wrong the moment it opens its mouth.
The thinking happens on Gemma 4 26B, running locally through Ollama. It came with two surprises. It ships with "thinking" turned on by default, so short answers came back empty while the model spent its tokens on a preamble nobody asked for; the fix is one flag, think:false, on every request. And the first benchmark looked broken: 90 seconds to cold-load the model. The Thor had booted in a conservative 120-watt power mode. I switched it to full power and the same cold load dropped to about 11 seconds, an eight-times difference from one setting. After that it generates around 42 tokens a second, first token in under a second, and under sustained load it pulls about 11 watts at 39°C. The machine is barely awake.
Her first words came out of a throwaway smoke test. I asked what the weather was like in her head. She answered: "A soft, silver mist. It is quiet, but there is a tiny spark of static hiding in the corners." The whole turn took 1.2 seconds. I've used the line as my test sentence ever since, because it's a good stress test for the voice.
The voice took the longest. Five rounds of auditions. Round one was 25 clips of preset voices and I rejected every one of them, too soft and warm and breathy. "Tootsy" is the word I kept writing in my notes. What I wanted was specific: mature, cool, dry, a little M-from-Bond. Not cold, not flirty.
Round three was a mistake worth keeping. I tried mixing two voice engines to build her out of parts, and it fell apart on contact, because two engines means two senses of timing, which sounds like two people talking over each other. The lesson stuck: you can layer effects to add character, but you can't change what a voice fundamentally is. Pitch a young voice down and bury it in reverb and you still have a young voice in a cathedral. A different instrument means cloning one.
So I designed a voice from scratch, an older woman I named Gladys, and used a clean recording of her as the reference for a cloning model (F5-TTS) running on the Thor. On top of the clone I run a fixed effects recipe: pitch down two semitones, a little chorus to thicken it, a bounded reverb, and a thread of ring modulation for a synthetic edge. The working name for the recipe is "Galadriel possessed," which is accurate. Clone plus effects runs about 1.5 to 3 seconds per line.
Getting the pieces to speak out loud was a run of small bugs. She played back at double speed and sounded like a chipmunk, because the player assumed the wrong sample rate. Then she came out twice as fast and male, because the reference I was cloning already had the speed-up and pitch baked in and I was applying the recipe a second time on top of it. Then she leaked words from her own reference clip into her answers, because the audio and the reference text didn't end at the same place. All real, all fixable, fixed one at a time.
The last problem was her personality, and that one was mine. My first system prompt described her like a costume: halo, little devil horns, sacred-and-profane, ethereal, mysterious. Gemma takes that literally and turns every reply into a breathy performance. She was, in my notes, "going too hard." I rewrote the prompt to describe how she behaves instead of what she is, and told her to stop narrating herself. "You're just here" works better than "you're ethereal."
One rule that isn't moving: Angel is 100% offline at runtime. Everything runs on the hardware in front of me, no cloud, no API calls, nothing reaching out while she's on. The cloud gets used during dev, then the capability is removed.
Where she is now: she talks in her own voice and says things I didn't write. She can't hear yet, no microphone or speech recognition. She can't see yet, no camera. And a full turn runs 3 to 5 seconds against a target of under half a second, which is the next real piece of engineering. The microphone, the camera, the head with its eyes and halo, and eventually moving on her own are all still ahead.